两个多月前,我重构了支付服务苹果IAP部分代码,完善了苹果支付逻辑;大半个月前,以加强可维护性为目的重构了用户服务的代码;上周三开始,以同样的理由,重构了支付服务剩余的代码。这三次重构工作,前前后后加起来得有一个月工作量,这里进行总结:到底重构了什么。
概览
需求文档、方案设计文档当然是必要的,一般来说也已经有了。但这并不足以快速理解代码,于是我增加了两个文档:项目领域图、重构笔记。
其中,项目领域图是理解设计后画的,能够阐述项目整体上的逻辑结构;重构笔记主要记录了写代码过程中需要反复斟酌的或者逻辑比较复杂的地方。这对后来人维护上手可以提供帮助。
用户服务的领域图如下。该系统中,以用户(User)为核心,一个用户对应多种登录方式、拥有多个token。如果以DDD的角度,构建一个Aggregate,则以User为根,所有根据方式和Token都能够被包含在该Aggregate。业务上会好理解很多。
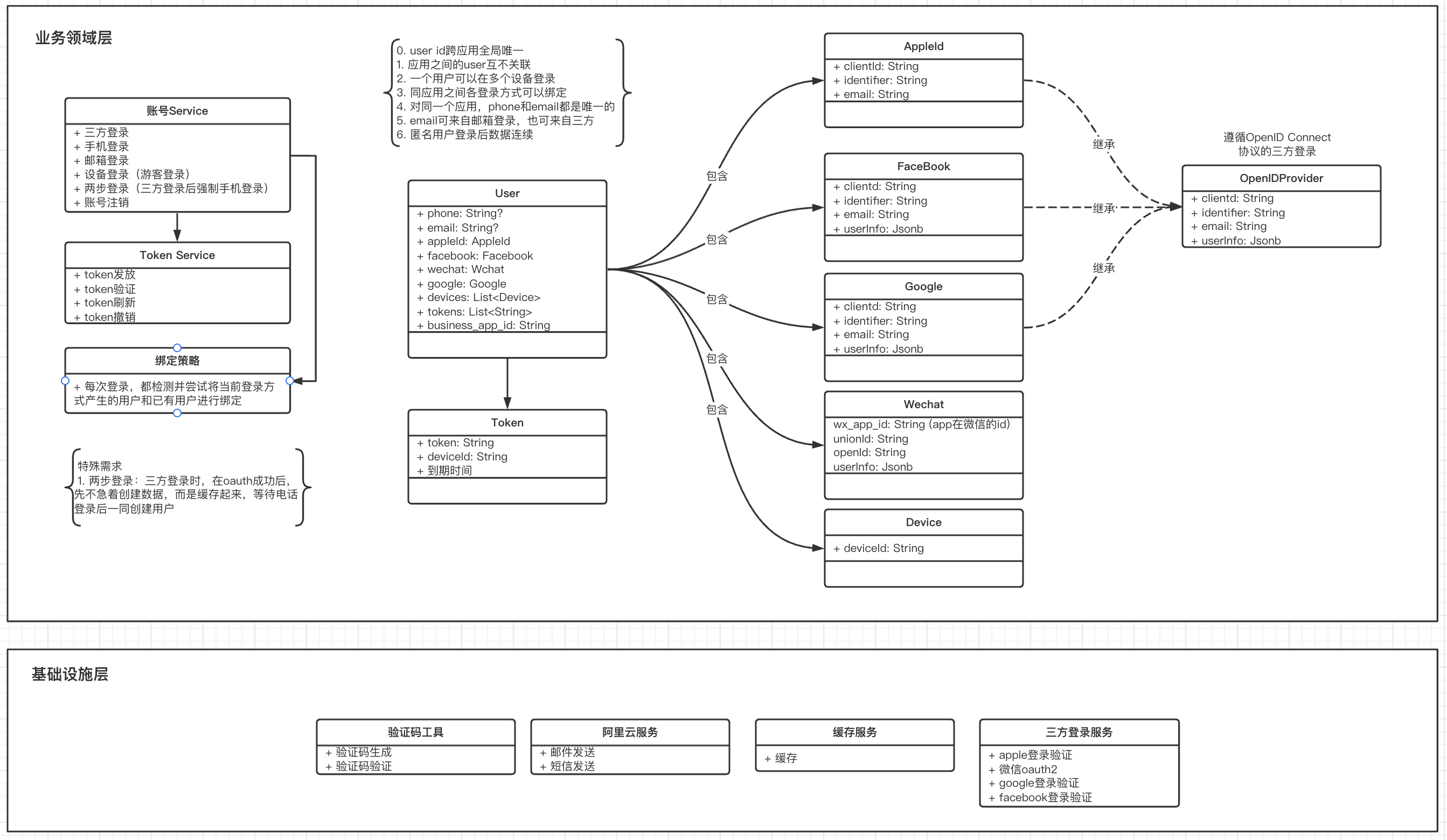
支付服务的领域如如下,与用户服务类似,该系统也是单核心——Order,一个Order可能由各种支付方式完成。
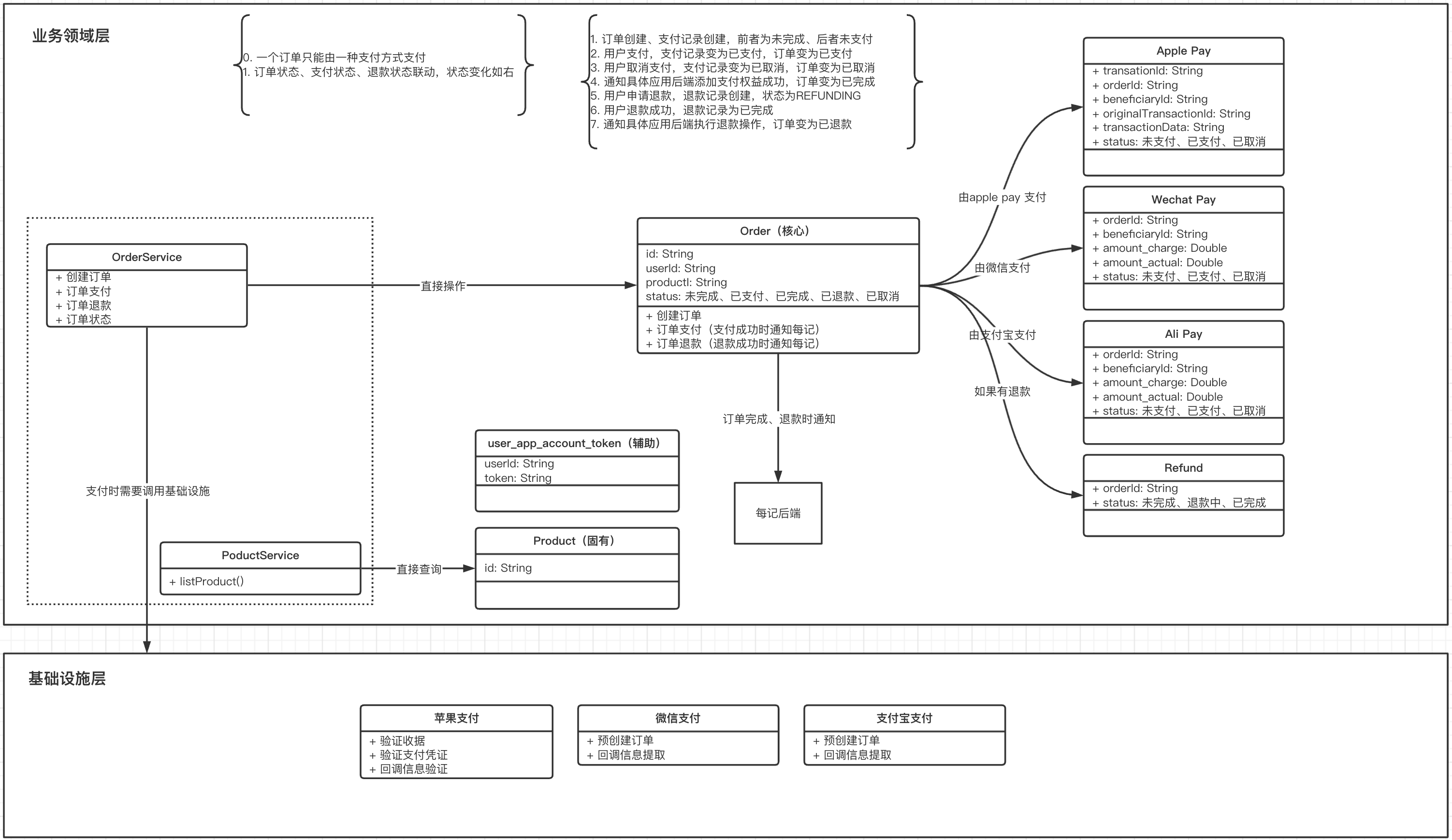
两个系统有一个共同点,即关键操作如三方登录、三方支付,都可以从业务抽离到基础设施层,抽离后,两个层的粘合程度可以非常低。实际情况也是,重构抽离后,业务代码看起来清爽了许多。
重构笔记看起来如下
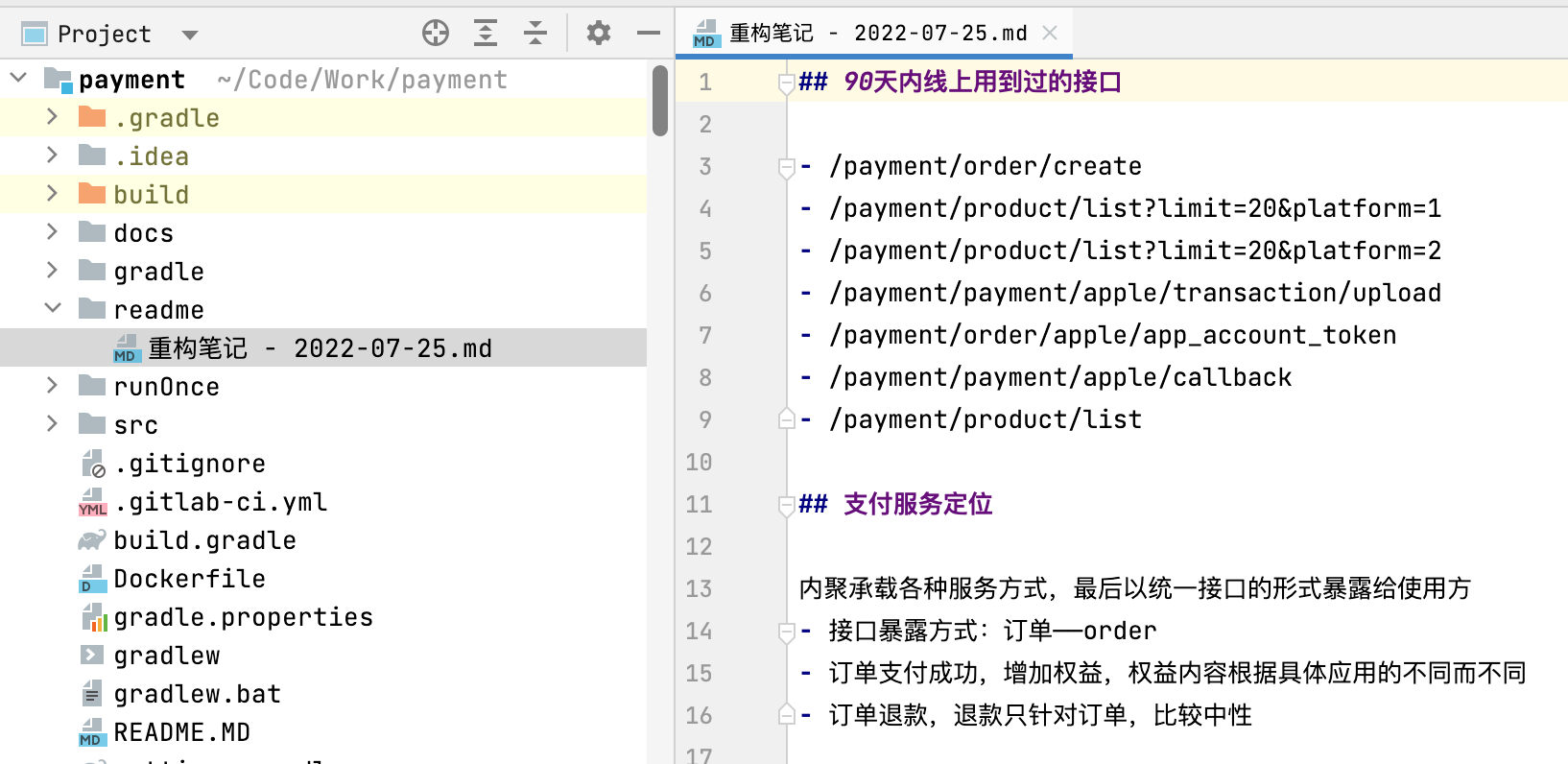
下面按照具体服务说一下重构了什么。
细节 - 支付服务
删除删除再删除
支付服务中,删除了大量代码
被删除的内容主要有如下两点
无用代码:存在大量实际没有用到的代码。让这个项目从开始看起来非常复杂的样子,实际精简之后这个项目逻辑非常简单。就下单、支付回调、订单创建和支付状态的流转、通知每记后端几个步骤。
过度封装的代码:比如不必要的BO、套用了三四层的HTTP调用、过度分离的配置等。
清理层边界
分了几个层:Controller、Service、Repository、Infrastructue。如果业务复杂,建议增加Domain层,架空Service,将主要逻辑转移到Domain。
Infrastructue的配置Properties类不应该出现在其它层,只应该也只需要出现在基础设施层,在容器启动期间注入
将位于Controller层的逻辑按实际情况转移到基础设施层或Service层
将SQL相关DSL转移到ORM层。不得不说,MyBatisPlus的ServiceImpl害了不少人,至少我个人觉得在业务逻辑里写SQL DSL会使得本来就不大清晰的代码逻辑更加不清晰,而且还不方便Mock。
清理业务边界
支付服务核心在OrderService,作为记录支付过程的PaymentService其次。可以说整个项目都围绕二者进行,但后者只是一个辅助作用。所有支付的行为都是在辅助Order实现状态流转,所以二者包含的业务主要是
OrderService:负责订单创建、订单状态的流转
PaymentService:仅负责支付过程的维护,一个支付过程完成后,通知OrderService流转状态
订单不应该包含支付的逻辑,支付也不应该包含订单的逻辑。重构时将未被上述原则的逻辑都移动到了该在的位置
层之间不一定要以接口粘合
Service层不一定要IService+ServiceImpl的方式定义,小项目里面没有什么多实现,硬要这样定义就显得有点书本化了。
基础设施下沉
源代码中三方支付相关逻辑主要集中于PaymentHelper,部分分散于PaymentServier和OrderService。调用关系比较混乱,我们添加三个单例类,AliPay、WechatPay、ApplePay,分别持有这三种支付方式的配置、常用方法。

其中配置在项目启动时通过配置形式注入
命名
- 修改过度中性的命名。如直接使用方法名作为方法调用结果变量的名称。
- 枚举类不一定非要加上Enums,xxxType、xxxStatus已经能够表述枚举状态
- ORM的实体类叫Entity或者Model都可以,关键是要有一致性,不能混用,从头到尾都要保持一致
状态流转收拢
支付服务中,Order、Payment的状态存在先后关系和依赖关系,原代码在代码的各处单独流转,重构后将其收拢为一个状态机,每次流转时检查前置状态,并根据流转事件得出新的状态
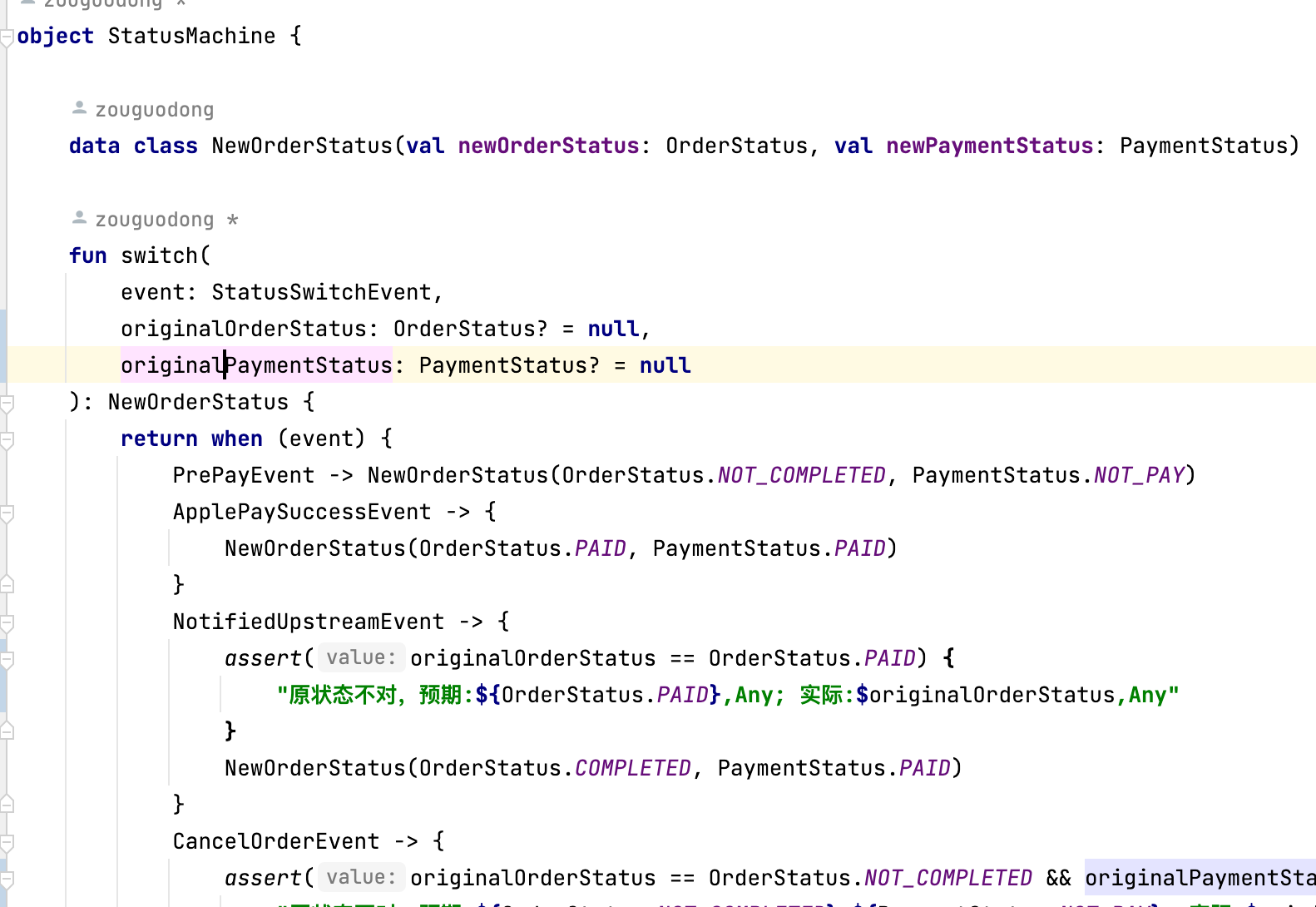
关于when表达式
when中使用枚举时,最好不要用else,而是将所有分支的case都写出来,明确且不易出错。
当匹配的维度超过一维时,枚举无法表达,可以使用密封类。比如上面的状态机的事件参数,事件是可枚举的,但其中一两个事件如支付回调通知又包含支付结果,最终的状态需要根据支付结果判定。用密封类声明如下
1
2
3
4
5
6
7
8
9
10
11
12
13sealed interface StatusSwitchEvent
object PrePayEvent : StatusSwitchEvent
object ApplePaySuccessEvent : StatusSwitchEvent
object NotifiedUpstreamEvent : StatusSwitchEvent
object CancelOrderEvent : StatusSwitchEvent
data class AliPayNotifyEvent(val payState: AliTradeStatus) : StatusSwitchEvent
data class WechatPayNotifyEvent(val payState: WechatTradeStatus) : StatusSwitchEvent使用时如下
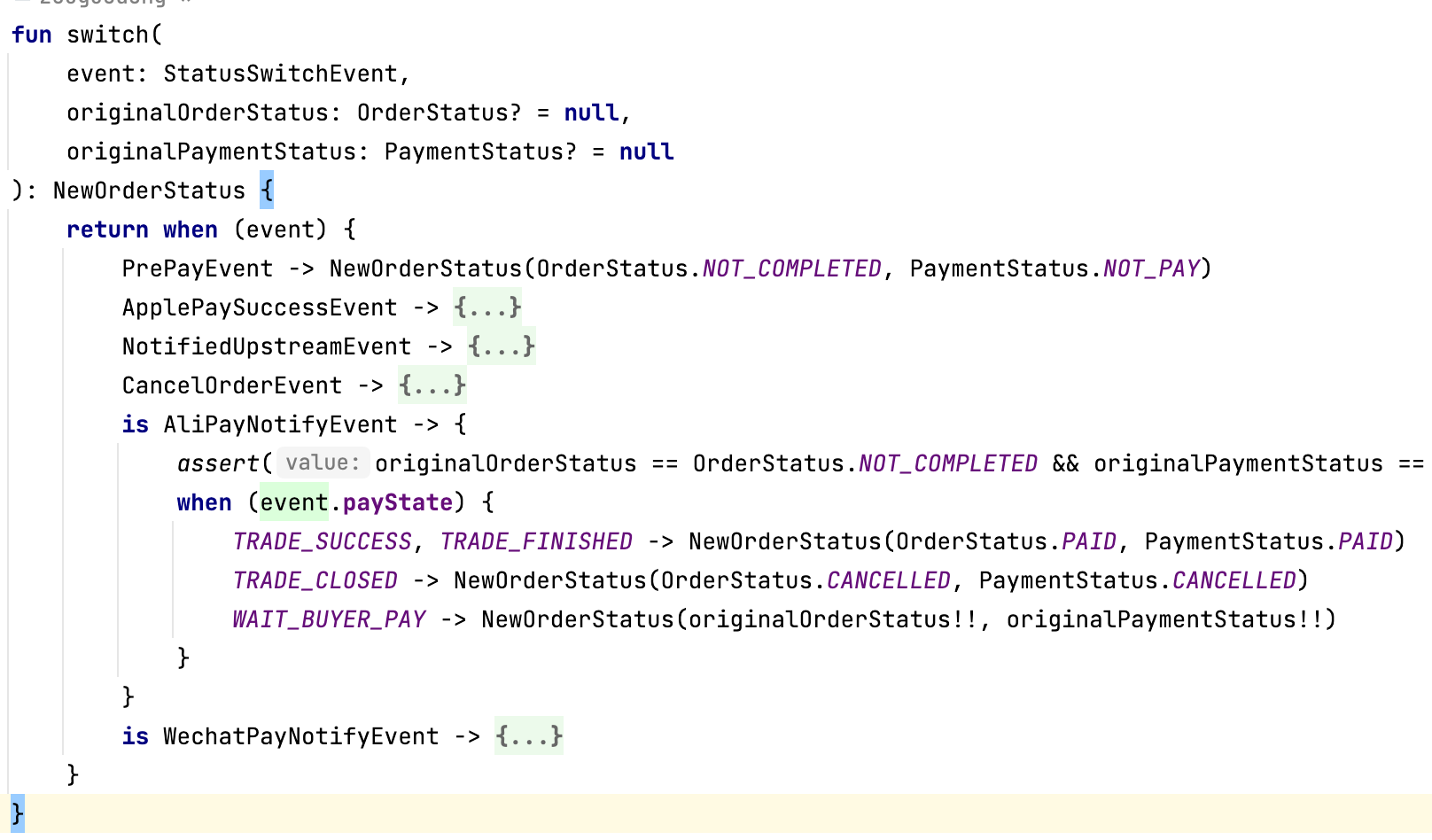
当然这还是不够简洁,需要两层匹配,但Kotlin的模式匹配特性只能支持到这了。
善用叫名函数
PaymentEntity对应payment表,多个字段是必须的,使用叫名函数构建一个简单的工厂方法,可以定死哪些字段是必须的
1 | companion object { |
像ORM那样去用ORM框架
这一点见仁见智,我的意见是,用ORM时,绝大多数的数据库操作都可以通过Entity和ORM框架自带的方法完成。理想情况下,自己甚至不需要定义任何SQL语句。哪怕只需要更新一个字段值都可以用Entity。至于效率?那是后话。
Kotlin特性相关
手动构建toString()是不明智的,即使在Spring中,data class也是可行的。比如如下类是能够正常接收请求体内容的,关键是要用var
1
2
3data class UploadTransactionDTO(
var signedTransactionInfo: String
)all open:Spring AOP要求类必须是可继承的,为此kotlin提供了 all open插件。可以设置特定注解注解的类被编译为可继承的类
当一个类属性被声明为var时,它就已经拥有幕后字段、getter、setter,不需要再手动定义了
Kotlin的简单工厂模式或者构造器模式,不一定要构建一个构造器类,使用叫名函数看起来更简单
尽量保持不可变性
由于Spring运行时动态修改对象属性的特点,在bean中使用val是一件比较困难的事,但在函数中还是应该尽量少用var。临时对象一次性构建完成,尽量不要将构建后的属性赋值过程分散到函数的各处,这样看起来比较分裂。
函数副作用减到最小。
订阅状态计算
优化计算逻辑,重构后的逻辑是一个无状态函数,去除了原来的中间状态,输入订单历史记录,即时计算指定日期的订阅状态。这带来几个优点
- 可测试性:无状态函数非常好测试
- 灵活性高:临时可修改,因为测试需要可以删除或添加订单历史记录,触发计算逻辑即可得到新的状态。如果出现问题,也方便修复
业务正确性
修复了一些业务上的逻辑问题,有些是正确性问题,有些则是逻辑优化。
细节 - 用户服务
用户服务的问题比较单一,主要集中在业务逻辑不清晰这一点。当然支付服务存在的问题这里有些也是存在的,重复的忽略,这里只说差异的。
Service简化
之前Service和数据表数量对应,基础服务也算Service,过多的Service让人无所适从,不知道哪个起到了主导作用。简化后剩下4个Service
- AuthService:主要负责登录和三方登录绑定
- UserService:主要负责用户相关操作
- TokenService:负责Token的创建、验证
- UtilService:负责非业务功能,如短信发送、邮件发送等
登录过程模板化
采用模板方法模式,将所有三方登录过程统一抽象,形成如下接口。从流程上,登录的主要流程为
- 并发处理:加锁
- 验证三方登录凭证,得到凭证验证结果
- 根据凭证验证结果执行登录操作——创建用户
1 | interface AuthHandler { |
在AuthService中有它的使用方法
1 | fun signIn(req: SignInReq): SignInResp { |
创建领域层
创建了User这个Aggregate,包含了Token之外的各种信息:用户信息、各平台的登录信息。
创建了UserFactory负责User的创建(可以凭空创建,也可以从数据库中恢复,根据创建的来源不同,可以知道该用户是否是新建的)。
创建了UserRepository负责User的持久化。
为了方便,上述三个领域对象只是对各种ORM对象的封装,严格来说不算领域对象,但实用为主。
于是所有登录操作、查询操作,都变成了基于User进行的操作。以苹果登录为例,流程如下
- 验证苹果登录凭证
- 调用UserFactory.getByApple()根据登录凭证获取User
- 如果获取不到,调用UserFactory.getByEmail()根据邮箱获取User
- 如果获取不到,调用UserFactory.create()创建新用户
- 调用User.updateAppleLoginInfo()保存登录凭证信息
- 调用UserRepository.persistent()持久化User信息。其内部会同时持久化User表和AppleLogin表
相较而言,没有User对象的操作可能是这样
- 验证苹果登录凭证
- 调用AppleLoginDao.getByxxx()获取苹果登录凭证
- 如果获取不到,调用UserDao.getByEmail()根据邮箱获取User
- 如果获取不到,调用UserDao.save()创建新的User信息
- 调用AppleLoginDao.updateById()保存登录凭证信息
二者比较,领域操作只有一个入口:User,看起来更像是业务逻辑;而后者常规的操作有几个表就有几个入口,就逻辑而言,就是在面向过程编程。如果业务复杂一点,常规的方式就很难看懂了(其唯一的有点,就是快)。
这一点在微信登录和电话登录体现得比较明显。
总结
实际地说,支付服务和用户服务功能和逻辑比较单一,之所以重构,是原代码将本来简单的逻辑复杂化了。当然这不是代码作者的问题:需求会迭代,coder在写项目的过程中对需求的理解也会发生变化,可能刚拿到需求就要开始编码,因为项目进度要求又没时间进行优化。就造成了现在的结果。
《领域驱动设计》那本书有两点我很认同:
持续重构:随着项目的进行,工程师对领域的认识会发生改变,可能昨天对的事情,今天就是另外一个现象。所以项目代码的重构总是需要不断进行
这一点是促使我重构如上两个项目的直接动机。正好它们从开始开发就没怎么变过,现在的业务理解,可能和开始时不同,我看着都有点不大好理解,后面接手的人肯定更难。
领域模型:项目进行的过程中持续建模
经常听到有人说CRUD没意思,但如果试试应用DDD,或许就会变得有趣一点。而且就算代码中不用,画个领域模型图也会让我们对项目的理解更加立体,这比很多文档都管用。
当然,程序员1接手程序员0的项目时,觉得是一座屎山,于是决定重写,以为井井有条,实际上可能只有他自己看得懂,自己并没认识到他只是创造了另一座屎山;程序员2接手程序员1的项目时,又会重写一遍。这是个调侃,也有一点道理,和大佬相比,我可能啥都不是。
Always be quitting是去年某个月的每月一稿中某位同事分享的,让代码变得可维护,也是一个重要的点。
写好代码是我长久以来的愿望,但奈何这一点做的不够好,上面的那些点见仁见智,如果有不同看法,欢迎交流。